higher dimension knn
Hello Check the full project and the code here
Implementing algorithms from scratch is one of the best ways to understand what’s going on when we use them. Just plug in the scikit-learn implementation shouldn’t be enough.
Theory
When performing Time Series Forecasting, sometimes the data we want to forecast needs to be of higher dimension than usual.
For example, when forecasting the price of electricity, it can be useful to predict the hourly price of a whole day instead of forecasting each hourly price recursively.
The scikit-learn implementation only lets us predict float numbers, this implementation will let us predict arrays.
The algorithm is simple.
- Fit is saving the training data and providing a value for
n. - Predict is finding the closest
npoints on the training data (with respect to the chosen distance) and returning an average (or weighted average) of the corresponding training dependent variables.
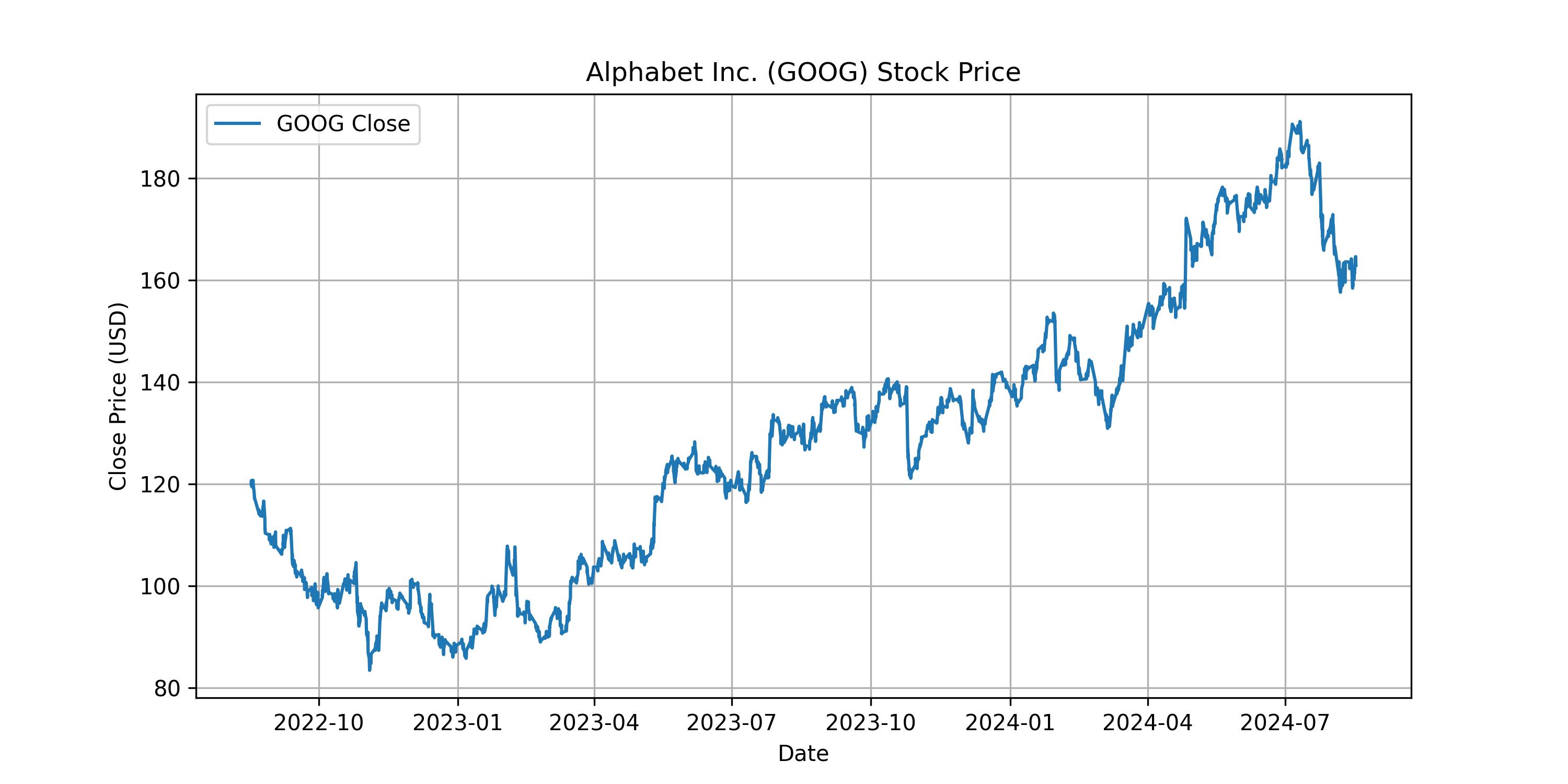
Example: hourly stock GOOG value
Firstly we need to get the stock price every hour. We use yfinance library to get the last 2 years with hourly data for GOOG.
Then we define our training dataset as three consecutive days, and the forth will be our dependent variable.
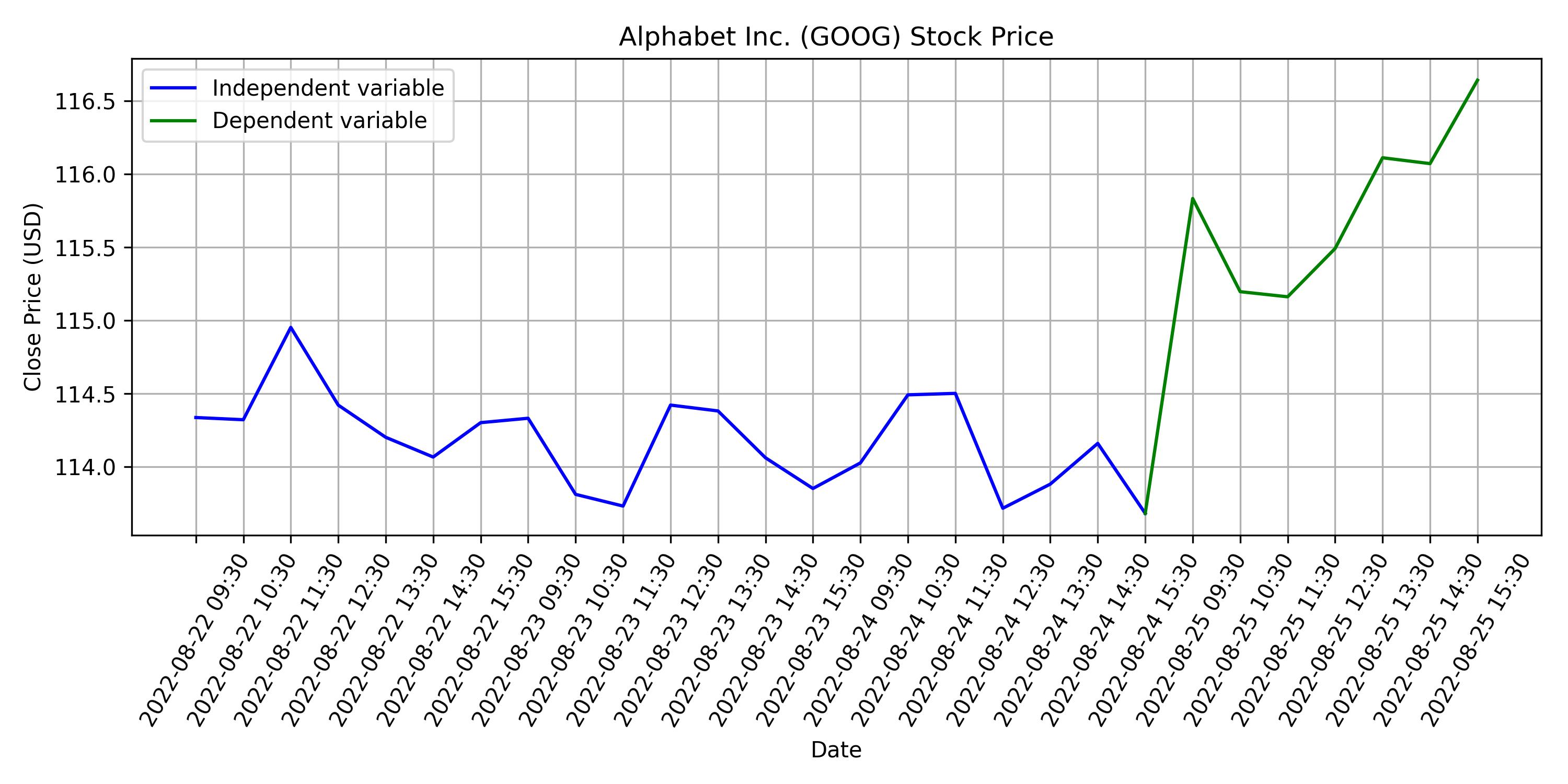
We split randomly the data, using 30% for test and the rest for training. Training is straightforward, as we don’t really need to find any parameter, we just need to save the training data.
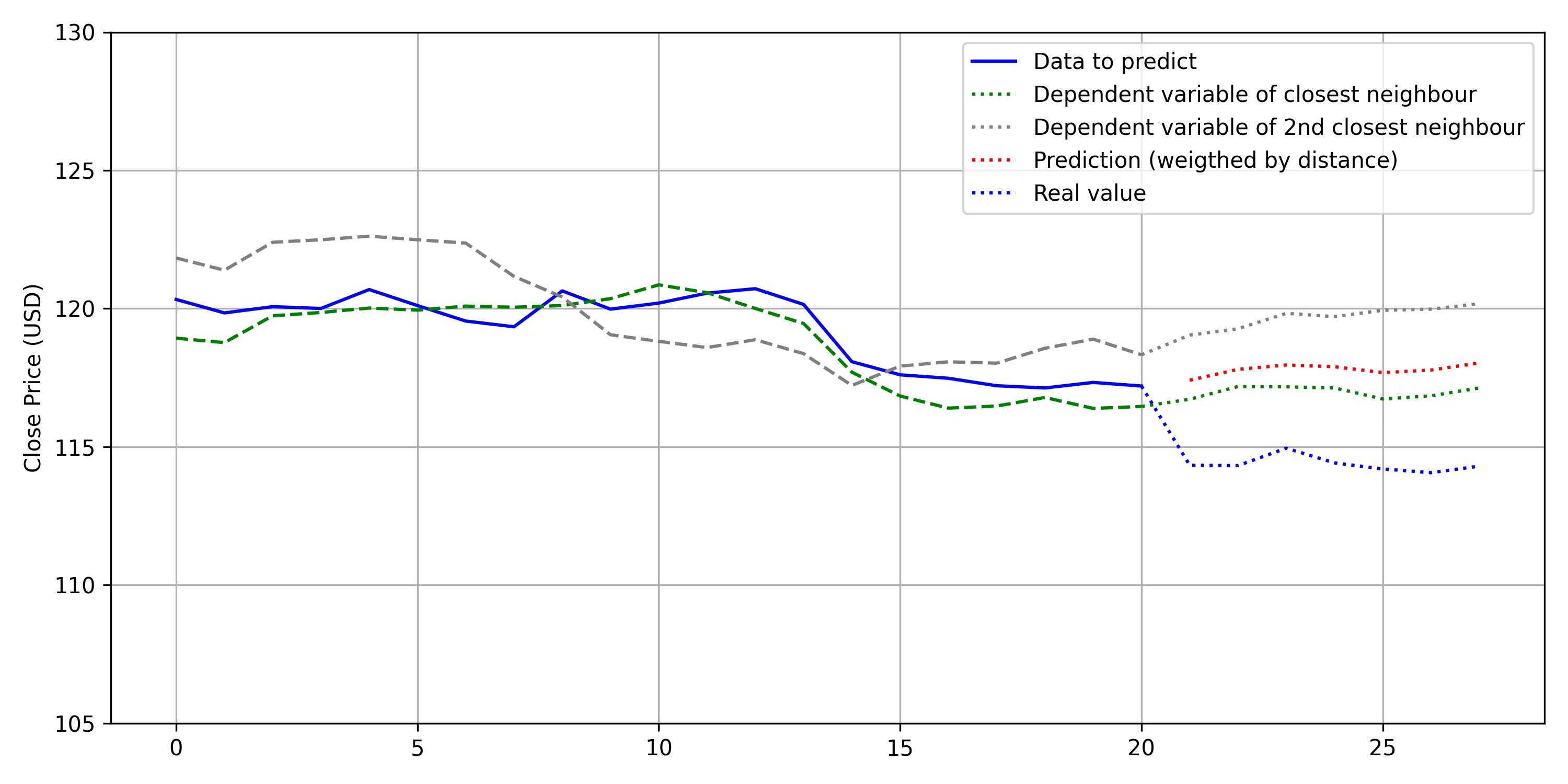
Let’s see how predicting works:
Take a point from the test dataset and get the 2 closest neighbors (from the training dataset).
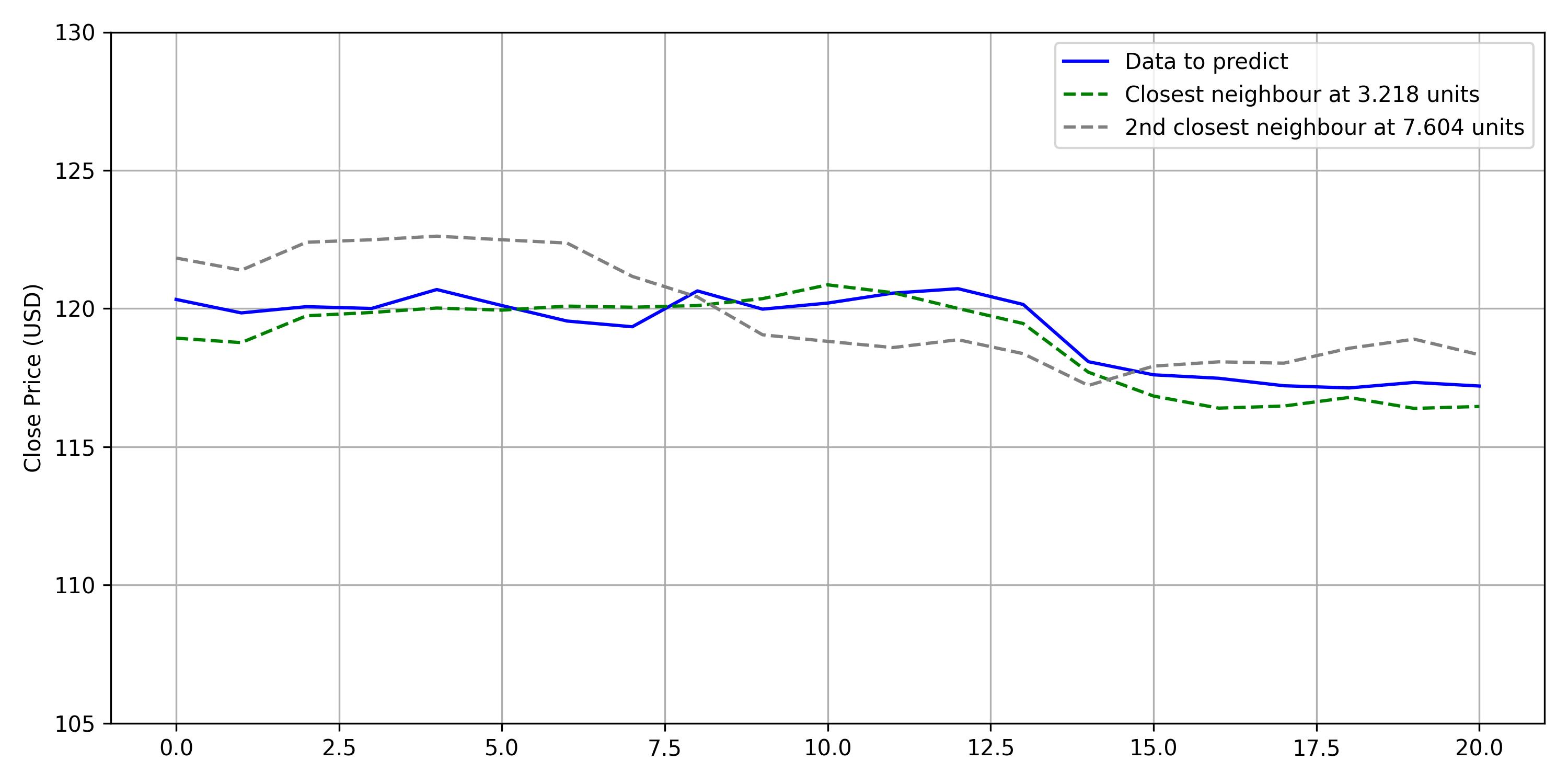
We look for the dependent variables of the nearest neighbours.
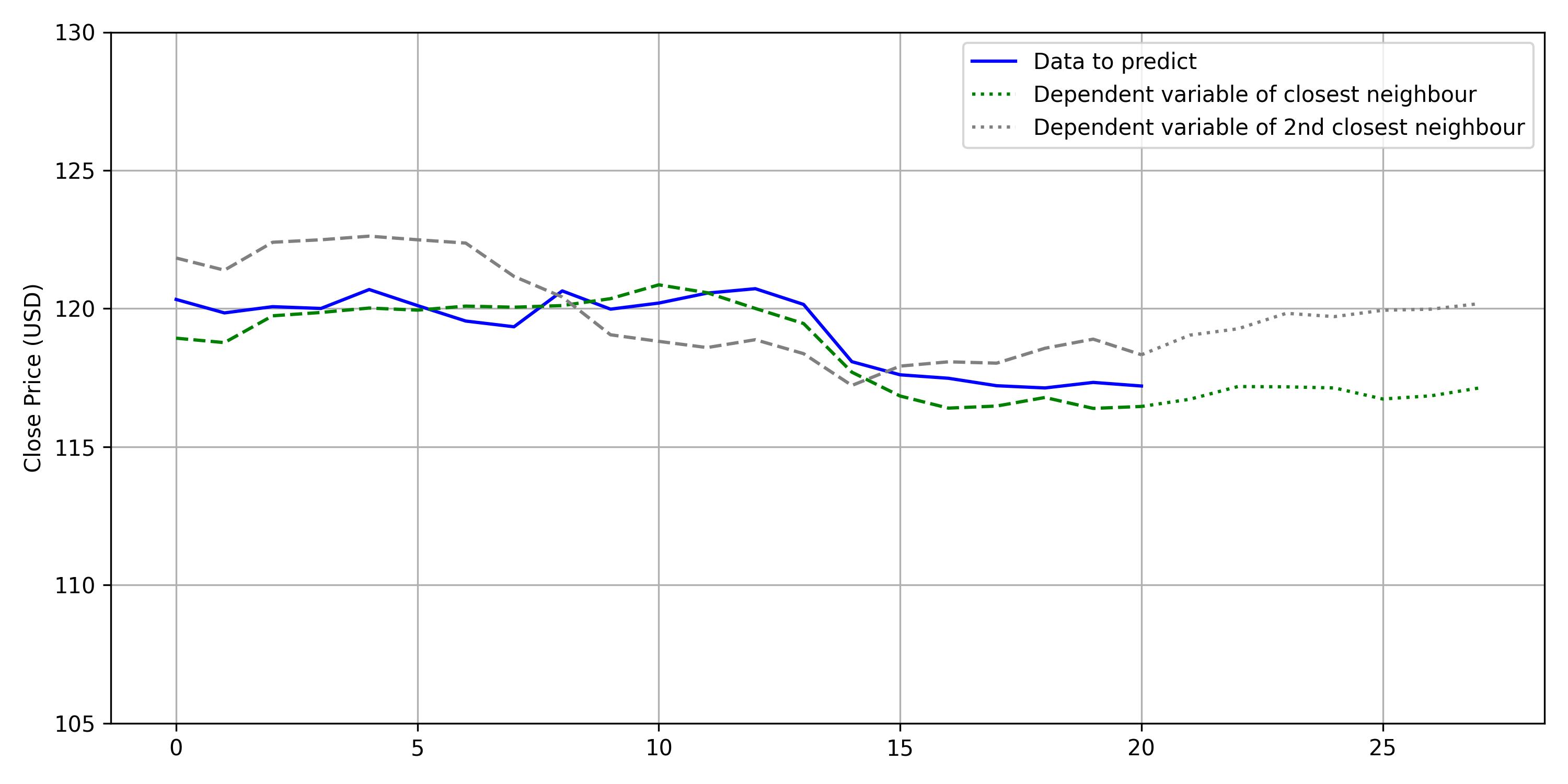
And make the weighted average to predict:
Notes
This is just an example to illustrate how the KNN algorithm can be adapted to higher dimensions, but does not compare the performance to other algorithms.